MySQL数据库分库分表方案
为什么要分库分表 当使用 MySQL数据库的时候,单表超出了2000万数据量就会出现性能上的分水岭。并且物理服务器的CPU、内存、存储、连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。为了解决这个问题,对大表进行分割,然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。实现方式: 垂直拆分和 水平拆分。
垂直分库
根据一个系统中的不同业务进行拆分 比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,一般要放在多个服务器上,而不是一个服务器上。分库的主要目的是解决单台mysql服务器性能瓶颈,放在一个服务器没有多大意义。 垂直分库如下图:将原来的一个数据库根据业务拆分成多个数据库
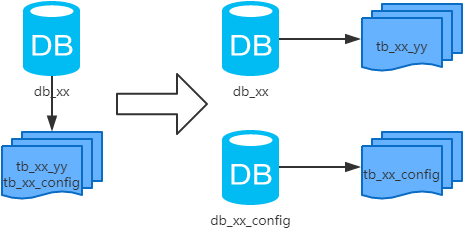
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了单机数据库的吞吐能力
分区方式,也不能解决单张表数据量暴涨的问题
但随着业务量的增大,垂直分库也不能解决单库数据量暴涨的问题,比如users数据库,用户量突破千万,这时候,垂直分库的方式也就无能为力的。这时候就需要再进行水平分库,进行水平扩展。
水平分库
将数据库中单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。可以水平扩展。
水平分库方式:
以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
水平分库结果:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
比如用户库按用户id范围分库, 将用户id在1-1000000的分到数据库db_user_0, 1000001-2000000分到数据库db_user_1, 2000001-3000000分到数据库db_user_2等等
分库顺序一般是先根据业务细分进行垂直分库,然后再进行水平分库。
垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。比如经常用到的将goods表拆分成goods表和goods_details表 垂直分表同垂直分库一样,会出现单表变大的情况,这时候需要利用水平分表策略
水平分表

概念: 以 字段为依据 ,按照一定策略(hash、range等),将一个 表中的数据拆分到多个 表中。
结果:
- 每个 表的 结构都一样;
- 每个 表的 数据都不一样,没有交集;
- 所有 表的 并集是全量数据;
场景
系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
分析
表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
分库分表工具
分布式数据库中间件分为两种,proxy和客户端式架构。 proxy模式有 MyCat、DBProxy等 客户端式架构有TDDL、 Sharding-JDBC等。
那么proxy和客户端式架构有何区别呢?各自有什么优缺点呢?
proxy模式的话我们的select和update语句都是发送给代理,由这个代理来操作具体的底层数据库。所以必须要求代理本身需要保证高可用,否则数据库没有宕机,proxy挂了,那就走远了。
客户端模式通常在连接池上做了一层封装,内部与不同的库连接,sql交给smart-client进行处理。通常仅支持一种语言,如果其他语言要使用,需要开发多语言客户端。
各自的优缺点如下:
分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)
分库分表问题以及解决方式
1.非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
除了partition key只有一个非partition key作为条件查询
映射法
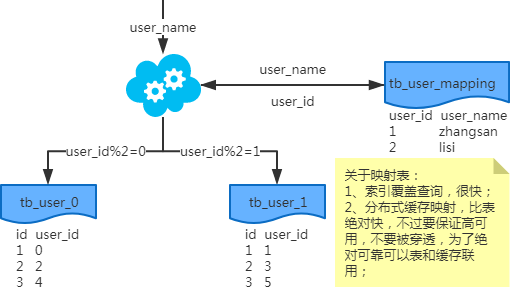
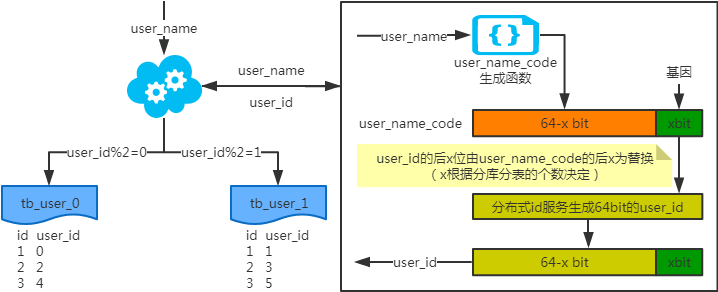
基因法
注:写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,2 3=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用 snowflake算法。
- 除了partition key不止一个非partition key作为条件查询
- 映射法
- 冗余法
注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。
- 后台除了partition key还有各种非partition key组合条件查询
- NoSQL法
- 冗余法
分库分表总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。
选key很重要,既要考虑到拆分均匀,也要考虑到非partition key的查询。
只要能满足需求,拆分规则越简单越好。
原文参考链接:https://blog.csdn.net/qq_39940205/article/details/80536666
https://blog.csdn.net/azhuyangjun/article/details/86976568
Working

标签
- 6676 Laravel配合Canal实现Elas...
- 2553 关于我的个人简介...
- 1915 Laravel修改线上env配置文件注意...
- 1890 Laravel快速接入 JWT 用户认证...
- 1785 关于宝塔搭建go线上环境以及项目部署...
- 1712 关于秒杀问题解决方法...
- 1706 fastadmin导入导出(需要php7...
- 1667 Laravel集成xunsearch...